Overview
推荐系统最核心的部分在于排序算法,也就是我们说的CTR预估问题。这部分算法在最近几年发展迅速,我们这篇文章,希望用经典的criteo数据集,和TensorFlow 2.0中的Keras模块,来演示一下DeepFM是怎么做CTR预估的。
1. 准备数据
在这里下载criteo数据集:Download Kaggle Display Advertising Challenge Dataset。
或者直接在终端下载,然后解压:
1 2 3 4 | mkdir criteocd criteowget https://s3-eu-west-1.amazonaws.com/kaggle-display-advertising-challenge-dataset/dac.tar.gztar -zxvf dac.tar.gz |
这个数据集,训练集40,000,000行,从readme.txt中可以知道数值型特征的有13个,类别型特征有26个,特征名称未提供,样本按时间排序。测试集6,000,000行,不含label。解压后,可以看到训练集是11.1G,测试集是1.46G。当前这个单机是打不开的。那我们就读取1,000,000条训练集好了。
1 2 | head -n 1000000 train.txt > criteo_sampled_data.csvcd .. |
2. 加载并处理数据
首先把抽样过的数据加载到内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import numpy as npimport pandas as pdfrom sklearn.preprocessing import LabelEncoder, MinMaxScalerimport tensorflow as tffrom tensorflow.keras import regularizersfrom tensorflow.keras.layers import *from tensorflow.keras.models import Modelfrom tensorflow.keras.utils import plot_modelimport tensorflow.keras.backend as Kfrom tensorflow.keras.callbacks import TensorBoardimport matplotlib.pyplot as plt%matplotlib inlinedata = pd.read_csv('criteo/criteo_sampled_data.csv', sep='\t', header=None)data.head() |
我们给数据加上列名:
1 2 3 4 5 6 | label = ['label']dense_features = ['I' + str(i) for i in range(1, 14)]sparse_features = ['C' + str(i) for i in range(1, 27)]name_list = label + dense_features + sparse_featuresdata.columns = name_listdata.head() |
2.1 处理连续型特征
1 2 3 4 5 | # 数值型特征空值填0data[dense_features] = data[dense_features].fillna(0)# 数值型特征归一化scaler = MinMaxScaler(feature_range=(0, 1))data[dense_features] = scaler.fit_transform(data[dense_features]) |
2.2 处理稀疏类别特征
1 2 3 4 | data[sparse_features] = data[sparse_features].fillna("-1")for feat in sparse_features: lbe = LabelEncoder() data[feat] = lbe.fit_transform(data[feat]) |
3. 建模训练
这个部分就是DeepFM模型的精髓所在。算法原理如图所示。
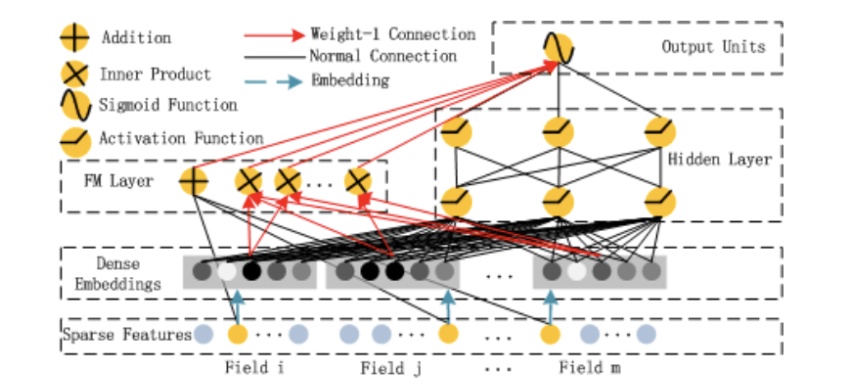
DeepFM模型是对Wide&Deep模型的改进。左边FM层和右边DNN层共享了Embedding层。
3.1 处理一阶特征
首先,数值型特征可以直接变成tensorflow.keras.layers.Input单元。
1 2 3 4 5 | dense_inputs = []for fea in dense_features: _input = Input([1], name=fea) dense_inputs.append(_input)dense_inputs |
数值型特征的生成的输入单元如下:
[<tf.Tensor 'I1:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I2:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I3:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I4:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I5:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I6:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I7:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I8:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I9:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I10:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I11:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I12:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'I13:0' shape=(None, 1) dtype=float32>]
连接成为稠密层:
1 2 | concat_dense_inputs = Concatenate(axis=1)(dense_inputs)first_order_dense_layer = Dense(1)(concat_dense_inputs) |
其次,处理稀疏类别型特征。
1 2 3 4 | sparse_inputs = []for fea in sparse_features: _input = Input([1], name=fea) sparse_inputs.append(_input) |
我们需要将稀疏特征Embedding成为稠密特征,需要用到tensorflow.keras.layers.Embedding模块,然后将其打平,这里是第一次对稀疏特征做Embedding,且映射成为长度为1的向量(还有一次映射):
1 2 3 4 5 6 7 | sparse_1d_embed = []for i, _input in enumerate(sparse_inputs): f = sparse_features[i] voc_size = data[f].nunique() _embed = Flatten()(Embedding(voc_size+1, 1, embeddings_regularizer=regularizers.l2(0.5))(_input)) sparse_1d_embed.append(_embed)sparse_1d_embed |
稀疏特征的生成的输入单元如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | [<tf.Tensor 'flatten/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_1/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_2/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_3/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_4/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_5/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_6/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_7/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_8/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_9/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_10/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_11/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_12/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_13/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_14/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_15/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_16/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_17/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_18/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_19/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_20/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_21/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_22/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_23/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_24/Identity:0' shape=(None, 1) dtype=float32>, <tf.Tensor 'flatten_25/Identity:0' shape=(None, 1) dtype=float32>] |
累加起来:
1 | first_order_sparse_layer = Add()(sparse_1d_embed) |
线性部分合并,即稠密层单元和稀疏层一维映射过的单元继续累加起来:
1 | linear_part = Add()([first_order_dense_layer, first_order_sparse_layer]) |
3.2 二阶特征
这里,我们只考虑稀疏特征映射后的二阶交叉,第二次对稀疏特征进行Embedding,映射到8维。其二阶FM的公式为:
n∑i=1n∑j=i+1⟨vi,vj⟩xixj=12k∑f=1[(n∑i=1Vif)2−n∑i=1V2if]
1 2 3 4 5 6 | sparse_kd_embed = []for i, _input in enumerate(sparse_inputs): f = sparse_features[i] voc_size = data[f].nunique() _embed = Embedding(voc_size+1, k, embeddings_regularizer=regularizers.l2(0.7))(_input) # 这里不要Flatten打平 sparse_kd_embed.append(_embed) |
第一步,把所有的8维向量拼接起来:
1 | concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) |
得到一个(26,8)的矩阵。
第二步,对该矩阵进行求和的平方:
1 2 | sum_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(concat_sparse_kd_embed)square_sum_kd_embed = Multiply()([sum_kd_embed, sum_kd_embed]) |
第三步,对该矩阵进行求平方和:
1 2 | square_kd_embed = Multiply()([concat_sparse_kd_embed, concat_sparse_kd_embed]) sum_square_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(square_kd_embed) |
第四步,求差除以2,再求和。
1 2 3 | sub = Subtract()([square_sum_kd_embed, sum_square_kd_embed])sub = Lambda(lambda x: x*0.5)(sub) second_order_sparse_layer = Lambda(lambda x: K.sum(x, axis=1, keepdims=True))(sub) |
至此,我们的FM部分完成。
3.3 DNN层
首先,我们把第二次Embedding之后的26个8维向量打平。
1 | flatten_sparse_embed = Flatten()(concat_sparse_kd_embed) |
然后,添加hidden layer并加上dropout:
1 2 3 4 | fc_layer = Dropout(0.5)(Dense(256, activation='relu')(flatten_sparse_embed)) fc_layer = Dropout(0.3)(Dense(256, activation='relu')(fc_layer))fc_layer = Dropout(0.1)(Dense(256, activation='relu')(fc_layer))fc_layer_output = Dense(1)(fc_layer) |
至此,DNN层结束。
3.4 合并输出层
我们把一阶部分和二阶部分,DNN输出层这三部分合并累加,然后用sigmoid函数将其和变成一个概率值。
1 2 | output_layer = Add()([linear_part, second_order_sparse_layer, fc_layer_output])output_layer = Activation("sigmoid")(output_layer) |
3.5 编译模型
模型构建:
1 | model = Model(dense_inputs+sparse_inputs, output_layer) |
打印出各单元和节点的关系图:
1 | plot_model(model, "deepfm.png") |
查看网络结构:
1 | model.summary() |
编译模型:
1 2 3 4 5 6 7 8 9 10 11 | model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])tbCallBack = TensorBoard(log_dir='./logs', # log 目录 histogram_freq=0, write_graph=True, # write_grads=True, write_images=True, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None) |
训练集和验证集按照8:2的比例划分:
1 2 | train_data = data.loc[:800000-1]valid_data = data.loc[800000:] |
处理稠密特征和稀疏特征,一定要分开处理:
1 2 3 4 5 6 7 | train_dense_x = [train_data[f].values for f in dense_features]train_sparse_x = [train_data[f].values for f in sparse_features]train_label = [train_data['label'].values]val_dense_x = [valid_data[f].values for f in dense_features]val_sparse_x = [valid_data[f].values for f in sparse_features]val_label = [valid_data['label'].values] |
模型训练:
1 2 3 4 5 | model.fit(train_dense_x+train_sparse_x, train_label, epochs=5, batch_size=256, validation_data=(val_dense_x+val_sparse_x, val_label), callbacks=[tbCallBack] ) |
输出训练过程:
1 2 3 4 5 6 7 8 9 10 | Epoch 1/53125/3125 [==============================] - 182s 58ms/step - loss: 30.0034 - binary_crossentropy: 0.5280 - auc: 0.6819 - val_loss: 0.6106 - val_binary_crossentropy: 0.5108 - val_auc: 0.7098Epoch 2/53125/3125 [==============================] - 181s 58ms/step - loss: 0.6243 - binary_crossentropy: 0.5168 - auc: 0.7051 - val_loss: 0.6414 - val_binary_crossentropy: 0.5092 - val_auc: 0.7157Epoch 3/53125/3125 [==============================] - 181s 58ms/step - loss: 0.6395 - binary_crossentropy: 0.5135 - auc: 0.7116 - val_loss: 0.6570 - val_binary_crossentropy: 0.5126 - val_auc: 0.7205Epoch 4/53125/3125 [==============================] - 180s 58ms/step - loss: 0.6475 - binary_crossentropy: 0.5123 - auc: 0.7143 - val_loss: 0.6674 - val_binary_crossentropy: 0.5059 - val_auc: 0.7229Epoch 5/53125/3125 [==============================] - 181s 58ms/step - loss: 0.6463 - binary_crossentropy: 0.5113 - auc: 0.7165 - val_loss: 0.6479 - val_binary_crossentropy: 0.5055 - val_auc: 0.7247 |
至此,DeepFM已经用TensorFlow 2.0实现。
本文主要参考了以下文章:
CTR预估模型:DeepFM/Deep&Cross/xDeepFM/AutoInt代码实战与讲解
CTR模型代码实战