Overview
本篇文章我们记录一下怎么用TensorFlow 2.0当中的Keras模块来进行RNN和LSTM文本分类。
1. 加载IMDB评论数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import tensorflow_datasets as tfdsimport tensorflow as tffrom tensorflow.keras import models, layers, losses, optimizers, Sequentialimport matplotlib.pyplot as pltdataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True, as_supervised=True)train_dataset, test_dataset = dataset['train'], dataset['test']encoder = info.features['text'].encoderprint('Vocabulary size: {}'.format(encoder.vocab_size))BUFFER_SIZE = 10000BATCH_SIZE = 64train_dataset = train_dataset.shuffle(BUFFER_SIZE)train_dataset = train_dataset.padded_batch(BATCH_SIZE)test_dataset = test_dataset.padded_batch(BATCH_SIZE) |
2. 构建RNN模型
1 2 3 4 5 6 | model = Sequential([ layers.Embedding(encoder.vocab_size, 64), layers.Bidirectional(layers.LSTM(64)), layers.Dense(64, activation='relu'), layers.Dense(1)]) |
其中,Embedding层是用来做word embedding的,把稀疏向量转换成稠密向量;Bidirectional层是一个RNN的双向封装器,用于对序列进行前向和后向计算。
3. 模型编译训练
1 2 3 4 5 6 7 8 9 10 11 | model.compile(loss=losses.BinaryCrossentropy(from_logits=True), optimizer=optimizers.Adam(1e-4), metrics=['acc'])history = model.fit(train_dataset, epochs=10, validation_data=test_dataset, validation_steps=30)test_loss, test_acc = model.evaluate(test_dataset)print('Test Loss: {}'.format(test_loss))print('Test Accuracy: {}'.format(test_acc)) |
测试集效果如下:
1 2 3 | 391/391 [==============================] - 109s 280ms/step - loss: 0.4388 - acc: 0.8553Test Loss: 0.43875041604042053Test Accuracy: 0.8552799820899963 |
画个图,看看效果:
1 2 3 4 5 6 7 8 9 10 | plt.rcParams['font.size'] = 14def plot_graphs(history, metric): plt.plot(history.history[metric]) plt.plot(history.history['val_'+metric], '') plt.xlabel("Epochs") plt.ylabel(metric) plt.legend([metric, 'val_'+metric]) plt.show()plot_graphs(history, 'acc')plot_graphs(history, 'loss') |
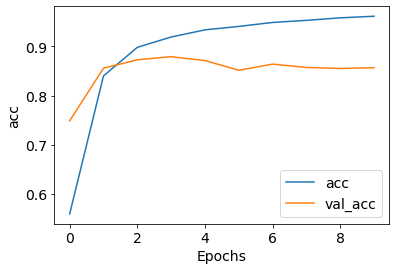
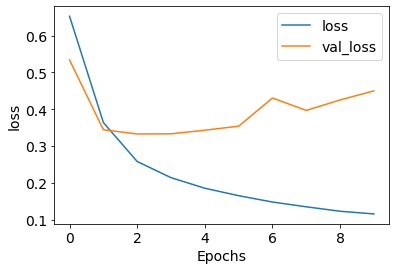
本文参考了如下文章:
Text classification with an RNN
TensorFlow 2 中文文档 - RNN LSTM 文本分类